
①はこちら
画像ファイルを取ってくる話。
「Screaming Frog SEO Spider」というソフトを使うやり方でやろうと思ってたんですけど、基本的に使いやすそうだしわからないところはないなぁって作業を進めてたんですけどね?どうにもリストに上がってくる画像ファイルの数が少ない。何かと思ったら、ちゃんとエラーっていうかアラートをだしてました。偉いソフトが何かって、ちゃんとエラーを報告できることだと思います。
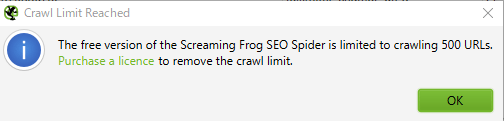
要はフリー版じゃ500個までしかリスト作らねーからな。っていうやつでして。画像以外の要素のURLも総当りでリストアップしていく上で500って数字はあんまり多くはないようで、私のブログ程度のデータでも途中でストップしてしまいました。
ちょっとこれ一回のためにお金出す気分にはなれなくてですね・・・。
というわけで別の手段を当たることにしました。
ばっちり。スクレイピングじゃなくて記事のエクスポートデータから直接引用URLを抜き出す手法なのでスクレイピングから画像リンクをすべて引っ張っちゃう場合と違って記事に挿入してる画像だけを引っ張れるので1つ目の方法よりもいいんじゃないかなと思います。このサイトでははてなフォトだけの想定だったんですけど、私はGoogleフォトもあるので検索条件にそれも含めてうまいこと落とせました。
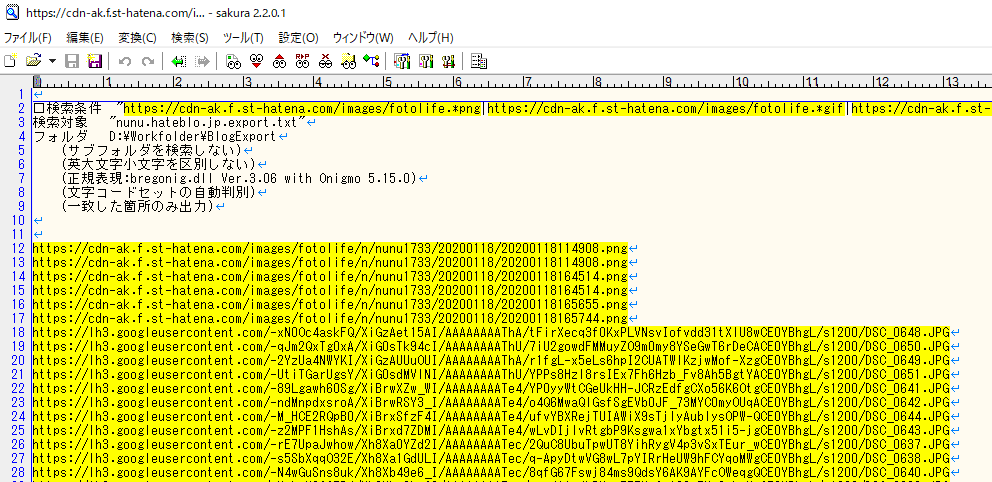
さらにはてなフォトの場合は画像の場所は一箇所にまとめられる仕組みのようでディレクトリの直下ファイル名だけで指定できるんですけど、GoogleフォトはなにやらGoogleの中でのフォルダIDのようなものが挟まるのでURLの置換がこの先大変になりそうだなと思っていたんですけど。
同サイトで紹介されているフリーのダウンロードツールには素晴らしいオプションが。
きみ最高。これでフォルダそのままサーバーに突っ込めばgoogleなんたらどっとこむのところだけ置換すればいけるはず。
今後のやること
こんな感じで画像の取得の流れはできたので、あとはサイト内のはてな依存の要素の除去・置換を済ませたらいよいよサーバー整備になりそうです。
ぱっと見たところ面倒そうなのはまずはてなキーワードのリンクが自動で色んな所で振られてるのを消さないといけないこと。これって読み込みのときに付与されてるのかと思ってたんですけど記事データレベルで挿入されてるんですね。

コメント